BunnyRL - Using PufferLib to Learn Source-Style Bunnyhopping
Try to beat the AI on this medium-difficulty bunnyhop course. The challenge: reach the end platform faster than the trained agent's best run.
What You're Playing
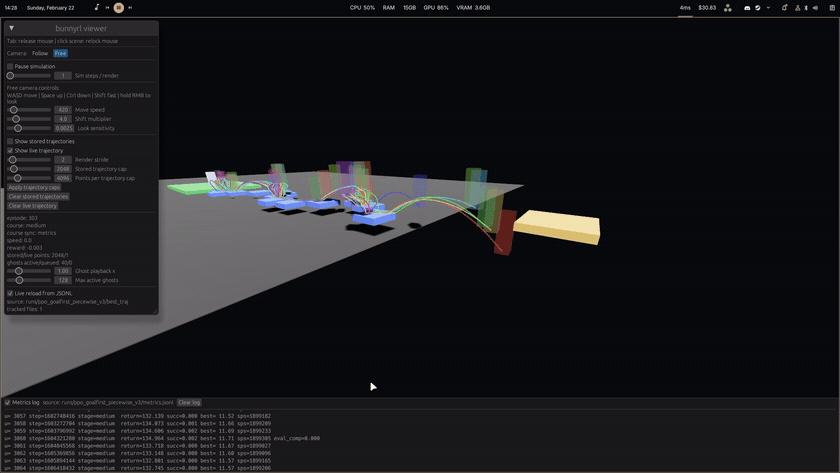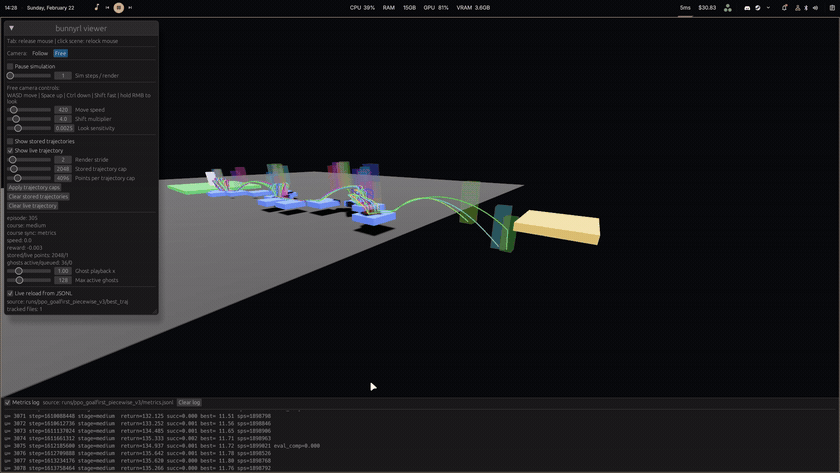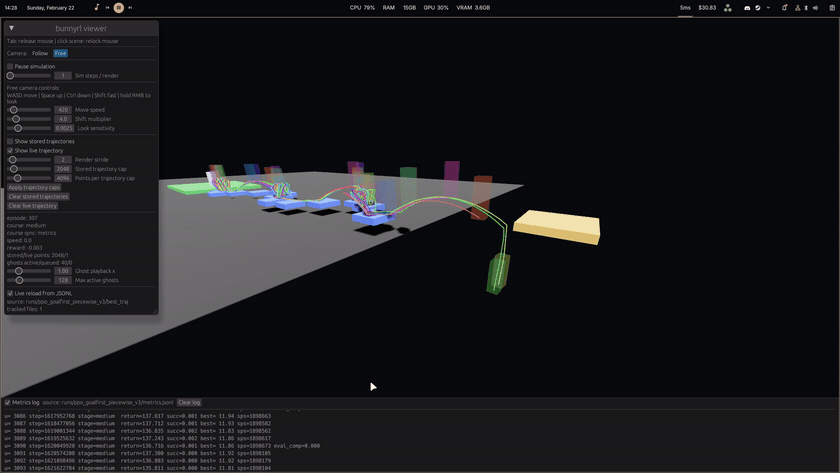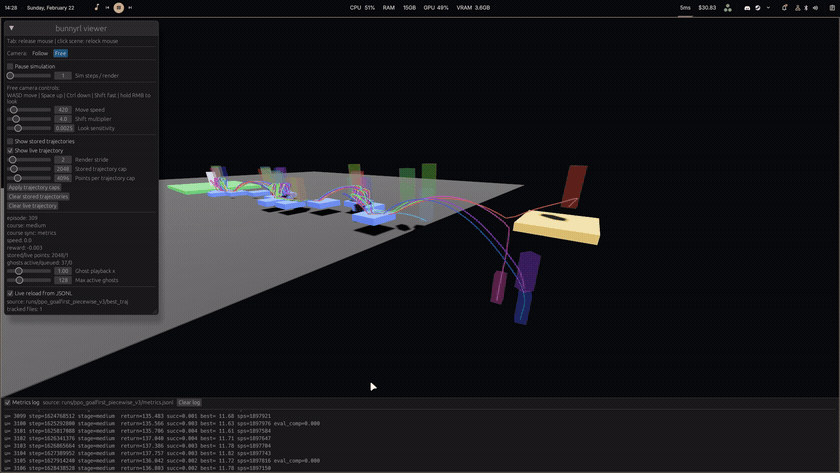
Bunnyhopping is all about chaining jumps while air-strafing to maintain and build speed. On this course, walking won't cut it. You need momentum to make it across the final gap and reach the finish.
Both the training environment and this playable demo run on the same shared Rust backend movement simulator, so what the agent learned is exactly what you'll experience.
How It Was Trained
An agent was trained using PPO and PufferLib in a 100 TPS simulator. The learning progression looked like this:
Throughput was high enough to iterate quickly: optimized headless env-only benchmarks ran at about 6.35M-7.09M steps/sec, while end-to-end PPO training in this run averaged about 1.84M steps/sec.
Reward shaping was centered on forward progress and sustained speed. Later runs added explicit incentives for skipping unnecessary platforms, plus anti-stall and anti-suicide penalties, so the policy favored fast route completion instead of safe but slow hopping patterns.
| Milestone | Global Steps | Wall Time | Sim Time |
|---|---|---|---|
| First completion | 1.6B | 13m | 186.7 days |
| Consistent finishes | 3.1B | 25m | 361.6 days |